Data Pipeline with Apache Airflow
ขั้นตอนการสร้าง Data Pipeline สำหรับดึงข้อมูลจาก API มาจัดเก็บภายใน Data platform
ในคู่มือฉบับนี้จะยกตัวอย่างการนำเข้าข้อมูล CRM Data จาก API มาจัดเก็บใน Data platform โดยใช้ Apache Impala ในการบริหารข้อมูล
สำหรับวิธีการพัฒนา Data pipeline ด้วย Apache Airflow ผู้ใช้งานสามารถศึกษาได้จาก คู่มือ Apache Airflow
ทดลองเชื่อมต่อ API
ศึกษาคู่มือการใช้งาน API ของข้อมูลที่ต้องการนำเข้า เช่น URL, วิธีการส่ง request (HTTP GET, HTTP POST และอื่นๆ), ลักษณะการรับ parameter ของ API, ลักษณะ respond ที่ API ส่งกลับมา เป็นต้น ตัวอย่างเช่น CRM API ใช้ REST API ผ่านทาง HTTP POST โดยรับ parameter เป็น JSON text และส่งข้อมูลกลับมาเป็น JSON text
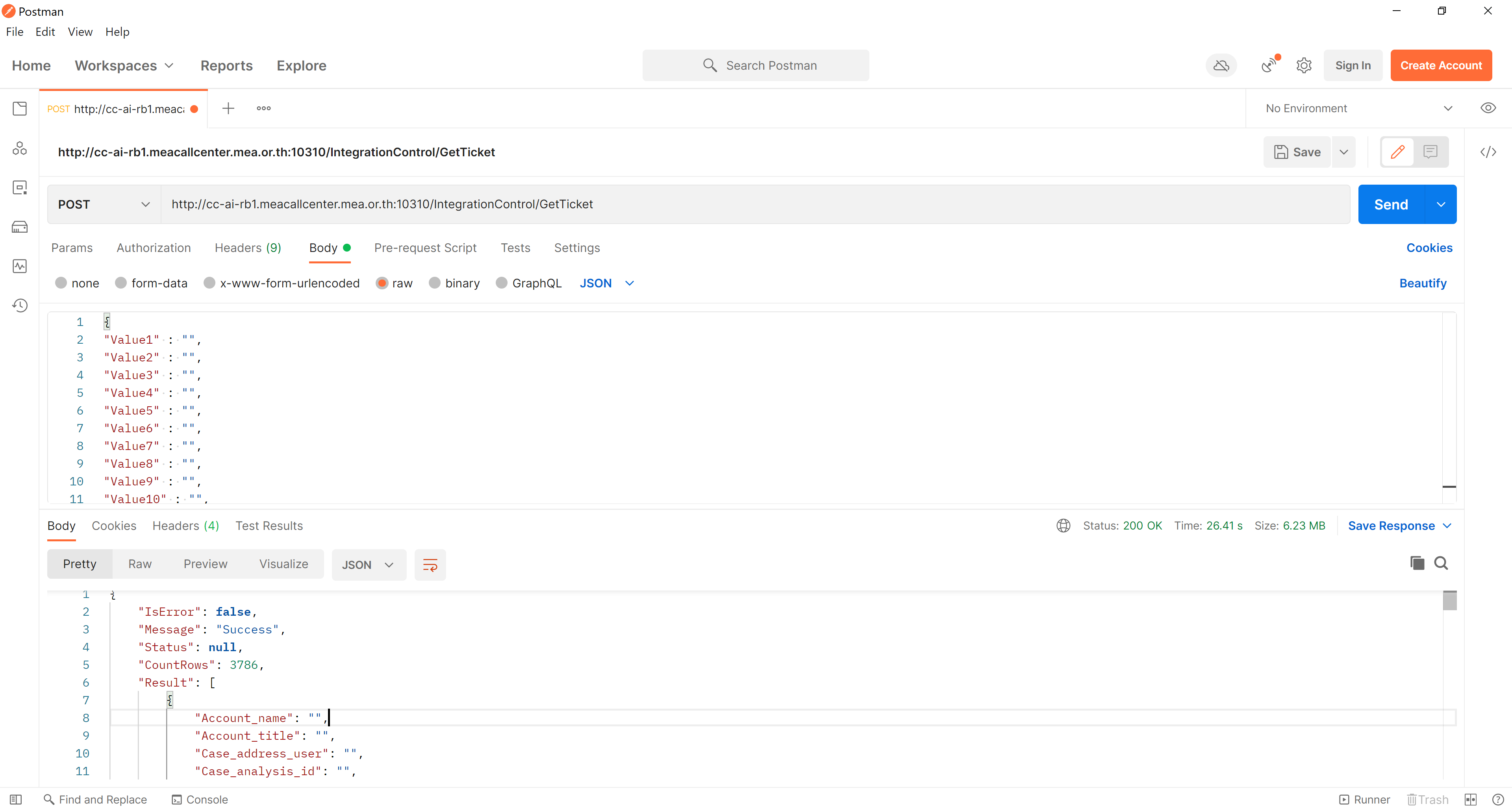
ก่อนทำการเขียนโค้ด สามารถทดสอบการดึงข้อมูลผ่าน API ผ่านโปรแกรม Postman ได้ โดยกำหนด request method, request parameter ตามที่คู่มือกำหนด
พัฒนา DAG
ทำการสร้างไฟล์ DAG และกำหนด parameter ต่างๆ ตามต้องการ
default_args = {
'owner': 'DPD',
'retries': 3,
'retry_delay': dt.timedelta(minutes=5),
'email': ['your.email@mea.or.th'],
'email_on_failure': False,
'email_on_retry': False,
}
with DAG(
dag_id = "DPD_Fetch_CRM_API_Data",
default_args = default_args,
description = "Fetch CRM daily data into TDV via API",
schedule_interval='@daily',
start_date = airflow.utils.dates.days_ago(1),
) as dag:สร้างฟังก์ชั่นสำหรับ request ข้อมูล api และเซฟเป็นไฟล์ csv โดย clean ข้อมูลและจัด format ให้เรียบร้อย python สามารถใช้ library requests ในการดึงข้อมูลผ่าน HTTP POST ได้ และใช้ library csv ในการแปลง python dictionary เป็นไฟล์ในรูปแบบ csv ได้
def _get_data_from_api(
url: str,
start_date: str,
end_date: str,
outfile: str
):
headers = {
'Content-Type': 'application/json'
}
params = {
'Value1': '',
'Value2': '',
...
}
res = requests.post(url, headers=headers, data = json.dumps(params))
if res.status_code == 200:
data = res.json()
#error handling
...
#cleaning data
...
output_dir = os.path.dirname(outfile)
os.makedirs(output_dir, exist_ok=True)
csv_columns = ['Account_name','Account_title', ...]
with open(outfile, 'w') as f:
writer = csv.DictWriter(f, fieldnames=csv_columns)
writer.writeheader()
for row in data['Result']:
writer.writerow(row)
else:
#raise http errorสร้าง task สำหรับดึงข้อมูลจาก api โดยใช้ function ที่เขียนไว้
get_data_from_api = PythonOperator(
task_id="get_data_from_api",
python_callable=_get_data_from_api,
op_kwargs = {
"url": 'http://cc-ai-rb1.meacallcenter.mea.or.th:10310/IntegrationControl/GetTicket',
"start_date": '{{ macros.ds_add(ds, -1) }}',
"end_date": '{{ ds }}',
"outfile": '/shared/crm-api/{{ ds }}-crm-tickets.csv',
}
)สร้าง task สำหรับสร้างตารางใน Apache Impala โดยใช้ JdbcOperator
create_crm_table = JdbcOperator(
task_id='create_crm_table',
jdbc_conn_id='sys-jdbc-impala',
sql="""
CREATE EXTERNAL TABLE IF NOT EXISTS crm_data (
Account_name STRING,
Account_title STRING,
...
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/airflow/crm-data'
TBLPROPERTIES ('skip.header.line.count'='1')
"""
)สร้างฟังก์ชั่นสำหรับอัพโหลดไฟล์ csv จาก airflow เข้า HDFS โดยใช้ WebHDFSHook
def _upload_file(
infile: str
):
webhdfs = WebHDFSHook(webhdfs_conn_id='sys-hdfs')
webhdfs.load_file(
source=infile,
destination='/user/airflow/crm-data/',
overwrite='true'
)สร้าง task สำหรับอัพโหลดไฟล์เข้า HDFS โดยใช้ function ที่เขียนไว้
upload_file_to_hdfs = PythonOperator(
task_id='upload_file_to_hdfs',
python_callable=_upload_file,
op_kwargs = {
'infile': '/shared/crm-api/{{ ds }}-crm-tickets.csv'
}
)สร้าง task ตรวจสอบว่าข้อมูลได้อัพโหลดขึ้นไปเรียบร้อยแล้วหรือไม่ โดยใช้ WebHdfsSensor
check_hdfs_upload = WebHdfsSensor(
task_id='check_hdfs_upload',
webhdfs_conn_id='sys-hdfs',
filepath='/user/airflow/crm-data/{{ ds }}-crm-tickets.csv'
)สร้าง task สำหรับอัพเดทข้อมูลตารางใน Apache Impala
refresh_data = JdbcOperator(
task_id='refresh_data',
jdbc_conn_id='sys-jdbc-impala',
sql="""
INVALIDATE METADATA airflow.crm_data
"""
)เชื่อม task ต่างๆ เข้าด้วยกัน
create_crm_table >> get_data_from_api >> upload_file_to_hdfs >> check_hdfs_upload >> refresh_data
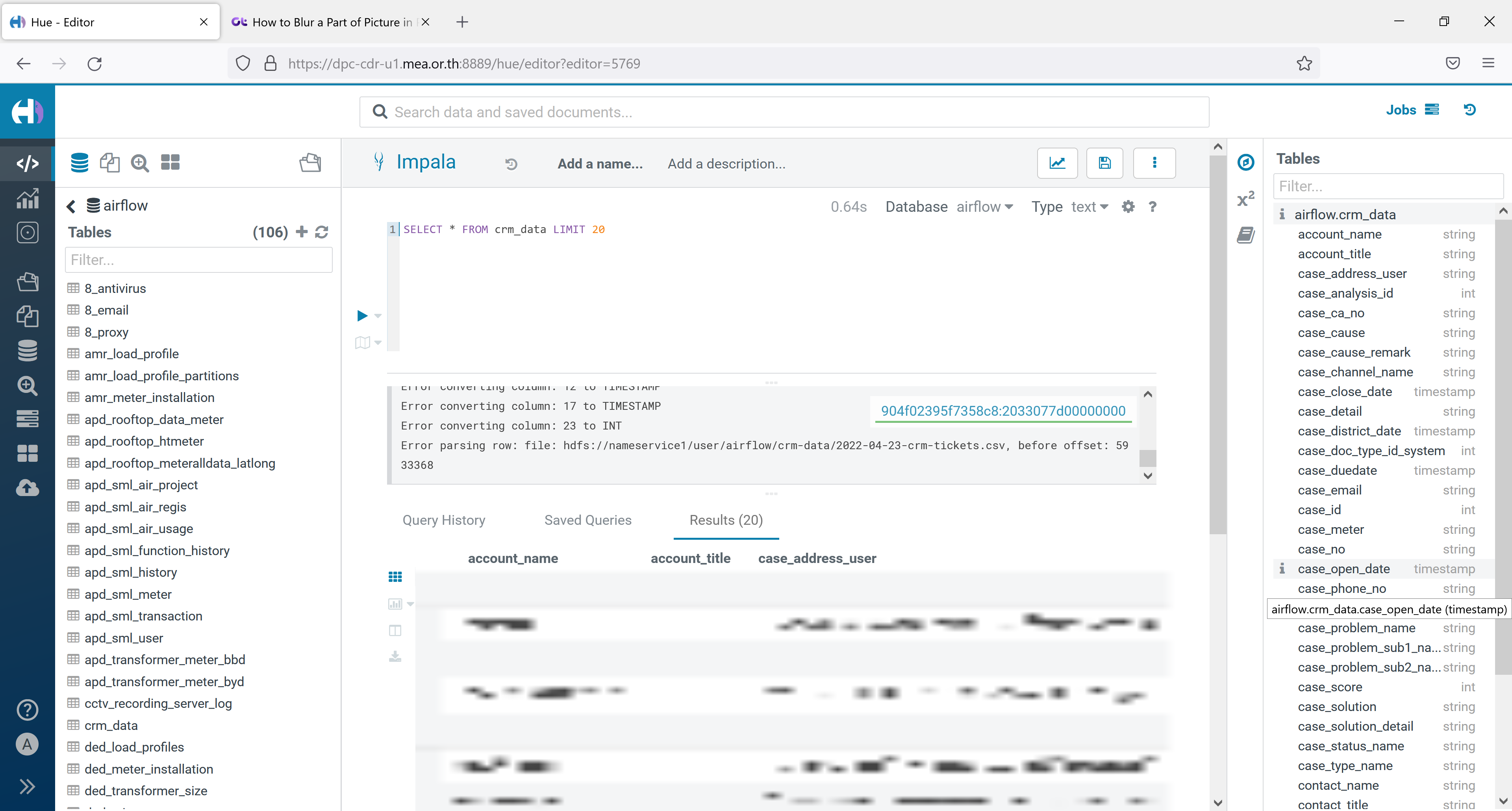
ตรวจสอบข้อมูลใน Hue
- ตรวจสอบข้อมูลใน Apache Impala ผ่าน Cloudera Hue โดยสามารถศึกษาวิธีการเข้าใช้งานได้ใน คู่มือ Cloudera Hue
ผู้ใช้งานสามารถดูตัวอย่างโค้ด DAG แบบเต็มได้ ที่นี่ (เข้าใช้งานได้ในเน็ตเวิร์ค กฟน. เท่านั้น)