การใช้งาน Apache Airflow
Apache Airflow คือ ซอฟต์แวร์ที่ช่วยบริหารจัดการ Data Pipeline คุณจะได้เรียนรู้เทคนิคการเขียนโปรแกรมเพื่อสร้าง Data Pipeline ในหลักสูตร Data Engineering Bootcamp คู่มือนี้จะอธิบายวิธีการเข้าใช้งาน Apache Airflow ภายใน กฟน. และ วิธีการ Interface กับ Data Sources ต่างๆภายในองค์กร
- Apache Airflow URL: http://airflow.mea.or.th:8080
- MinIO DAG Repo URL: http://172.17.113.251:9000
การเข้าใช้งาน Apache Airflow
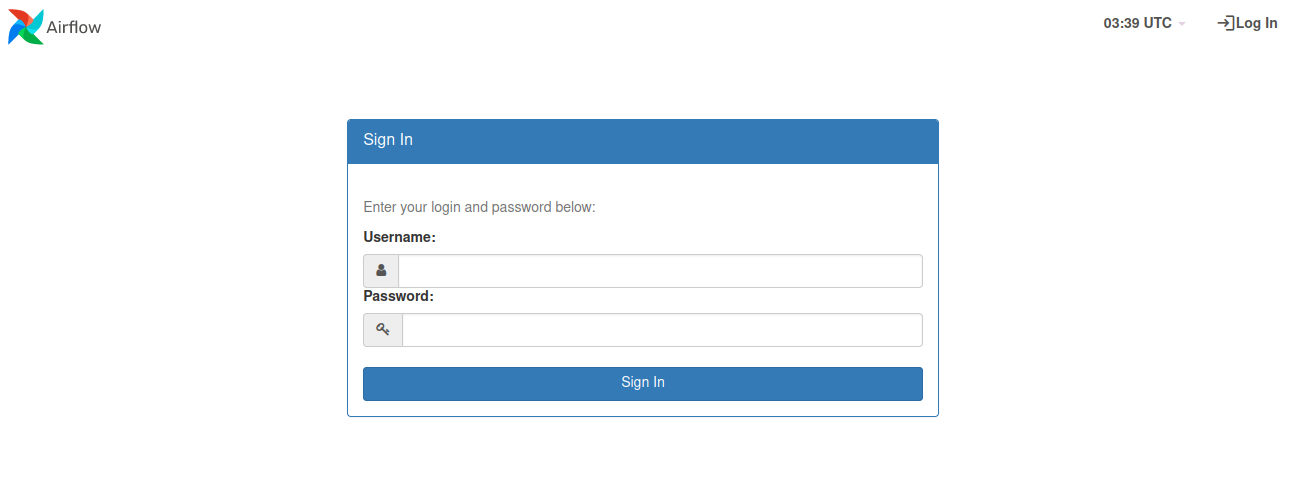
คุณสามารถใช้งาน Apache Airflow ได้ที่ URL: http://airflow.mea.or.th:8080 โดยจะต้องเข้าใช้งานผ่านเน็ตเวิร์กภายในของ กฟน. หรือ ผ่าน VPN เท่านั้น หลังจากเข้าเว็บไซต์แล้วจะพบหน้า Login ให้ใช้ Username และ Password จากระบบ AD ของ กฟน. (ที่ใช้ Login Computer/WiFi) เพื่อเข้าใช้งาน
การนำเข้า DAGs
คุณสามารถนำไฟล์ DAG ที่พัฒนาแล้วมาใช้ใน Airflow ของ กฟน. ได้โดยนำไฟล์ .py ไปใส่ไว้ใน Bucket ชื่อ dags ของ MinIO จากนั้นระบบจะทำการ Sync ไฟล์เข้า Airflow ภายใน 2 - 3 นาทีหลังจากวางไฟล์
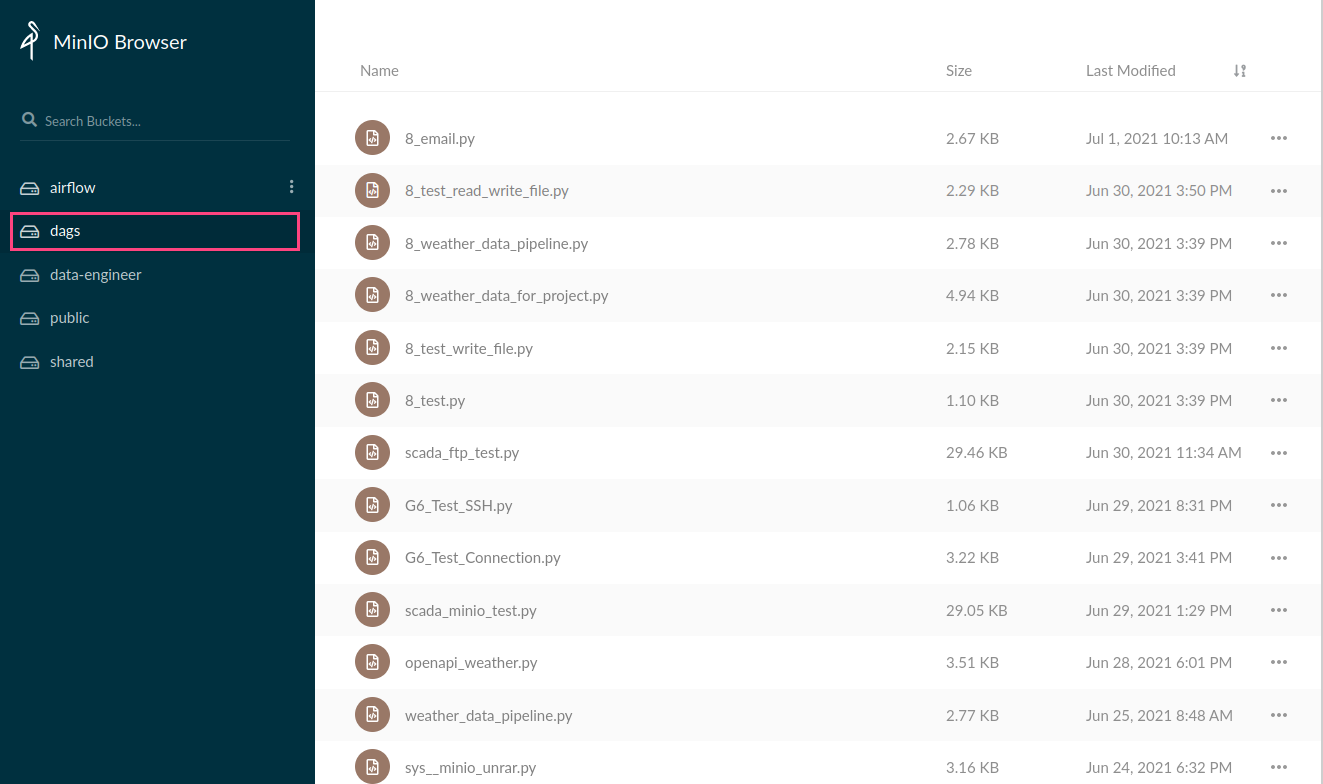
หากคุณต้องการลบ DAGs คุณสามารถลบผ่าน MinIO ได้เลย Airflow จะทำ Clean up DAGs ทุกวันเวลาเที่ยงคืน
การนำไฟล์เข้า Airflow
คุณสามารถนำไฟล์เข้า Airflow พื่อใช้ประมวลผลได้สองวิธี
- นำไฟล์ไปวางที่ Bucket
airflowใน MinIO จากนั้นคุณสามารถใช้ Python packageminio(ใน Airflow ทำการติดตั้งให้เรียบร้อยแล้ว) ในการดาวโหลด หรือ อ่านไฟล์จาก MinIO ได้โดยตรง - นำไฟล์ไปวางผ่าน SFTP ที่ Host:
airflow.mea.or.thPort:5436Username:airflowPassword:airflowโดยไฟล์ที่อัพโหลดผ่าน SFTP สามารถเรียกใช้ใน Airflow ได้ที่ Path:/sharedตัวอย่างเช่น คุณอัพโหลดไฟล์ชื่อmydata.csvในโฟลเดอร์ Shared ใน SFTP เวลาอ่านไฟล์ใน DAG คุณสามารถใช้ Path:/shared/mydata.csv
ไดเรกทอรี่ shared สามารถเข้าถึงได้ทุกคนภายในหลักสูตร คุณไม่ควรเก็บข้อมูลส่วนบุคคล หรือ ข้อมูลที่มีความอ่อนไหว
สถาปัตยกรรม Apache Airflow
กฟน. Deploy Apache Airflow ใช้ Celery Executor มี 15 Workers สำหรับการประมวลผล แบบขนานและมีระบบคิวในการรัน Task โดยมี vCPU 92 Cores และ RAM 312GB ซึ่ง
- เหมาะกับการประมวลผล Python Code ทั่วไป ขนาดข้อมูลไม่ใหญ่มาก การประมวลผลไม่ซับซ้อนมาก
- หากต้องการประมวลผลข้อมูลขนาดใหญ่ ขอให้ใช้ Apache Spark ใน Data Platform แทน
- โดย Default กฟน. ลงทุก Connectors ลง Python packages ที่นิยมและจำเป็นต้องใช้ หากพบ
module not foundคุณสามารถแจ้งปัญหามาที่ ฝวท. เพื่อลง Package เพิ่มได้ คุณไม่ควรจะ pip install เอง เนื่องจาก Airflow มีทั้งหมด 15 Workers และ ควรจะลงให้ครบทุก Worker เพื่อป้องกันปัญหาการรัน Task บน Worker ที่ไม่มี Package
สิทธิการใช้งาน
สิทธิการใช้งานของนักเรียน Data Bootcamp เป็นดังนี้
| สิทธิ | DAGs | Connections & Variables |
|---|---|---|
| Typical User | View only | - |
| Data Analyst | View only | - |
| Data Scientist | View only | - |
| Data Engineer | Create, Read, Update, Delete | Create, Read, Update, Delete |
สิทธิในการใช้งานของ Data Engineer เยอะกว่านักเรียน Data Scientist และ Data Analyst เพื่อให้สะดวกในการทำงานและเรียนรู้ ขอให้ระมัดระวังในการใช้อำนาจที่คุณมี
การเชื่อมต่อกับ Data Sources
โดยทั่วไป Apache Airflow จะไม่ได้เชื่อมต่อ (ไม่มี Route และ ไม่ได้ Allow Firewall) กับ Data Source ในหน่วยงานของคุณ หากคุณต้องการที่จะเชื่อมต่อกับระบบของคุณสามารถทำได้โดยแจ้ง ฝวท. ซึ่งทางทีมงานจะประสานงานกับทีมงานเน็ตเวิร์กใช้เวลาประมาณ 2 - 3 วัน อย่างไรก็ตามคุณสามารถศึกษาวิธีการเขียนโปรแกรม Python เพื่อ Interface กับ Databases และ Data Platform ได้ตามรายละเอียดด้านล่าง
Development Databases
ใน Airflow มี Development Databases ให้คุณใช้เพื่อทำการทดสอบ Operator หรือ ฟังก์ชั่นต่างๆก่อนที่จะใช้งานกับระบบจริงของคุณ โดยคุณมีสิทธิ CRUD เต็มรูปแบบ ปัจจุบันมี Databases 3 ประเภทให้ใช้งาน
- PostgreSQL ใช้งานได้โดยกำหนด
conn_id='dev-postgres' - MariaDB ใช้งานได้โดยกำหนด
conn_id='dev-mysql' - MongoDB ใช้งานได้โดยกำหนด
conn_id='dev-mongodb'
Oracle Databases
การเชื่อมต่อ Oracle สามารถทำได้โดยการใช้ Module cxOracle ร่วมกับ sqlalchemy ซึ่งได้ติดตั้งไว้เรียบร้อยแล้ว ใน DAG ของคุณสามารถกำหนดวิธีการเชื่อมต่อ และ ทำการ Query ด้วย pandas ได้ทันที เช่น:
from sqlalchemy import create_engine
import pandas as pd
USERNAME=<DATABASE_USERNAME>
PASSWORD=<DATABASE_PASSWORD>
HOST=<DATABASE_HOST>
PORT='1521'
SERVICE=<SERVICE_NAME>
# Create a connection string
conn_str = f'oracle+cx_oracle://{USERNAME}:{PASSWORD}@{HOST}:{PORT}/?service_name={SERVICE}'
conn = create_engine(conn_str)
pd.read_sql('SELECT * FROM <DATABASE_TABLE>', conn)
Development SFTP
ใน Airflow มี Development SFTP สำหรับให้ทดสอบเชื่อมต่อ อัพโหลด ดาวโหลด เข้าออกระบบ Airflow โดยสามารถใช้งานได้สองวิธี
ใช้งานภายใน DAG ได้โดยกำหนด
conn_id='dev-sftp'และไฟล์จะไปอยู่ในโฟลเดอร์/sharedของ Airflowต่อจาก SFTP Client ภายนอก (Network ภายใน กฟน. หรือ VPN เท่านั้น) เพื่อนำไฟล์เข้า Airflow โดยกำหนด
Component Value Host airflow.mea.or.th Port 5436 Username airflow Password airflow
โดยไฟล์ที่ถูกอัพโหลดผ่าน SFTP Client จะเข้าไปอยู่ในระบบ Airflow อัตโนมัติ และ สามารถเรียกใช้งานผ่าน Path /shared
คุณสามารถดูตัวอย่างการใช้งาน SFTP ใน Airflow ได้ใน DAG SFTP
WebHDFS
คุณสามารถเชื่อมต่อกับ HDFS บน Data Platform ได้โดยใช้ conn_id='sys-hdfs' ร่วมกับ WebHDFS API แต่ในสภาพแวดล้อมของ กฟน. นั้น Official Source Code ของ WebHDFS ยังไม่ซัพพอร์ตการเชื่อมแบบ Kerberized HTTPS ซึ่งเป็นระบบที่ กฟน. ใช้งาน คุณมีวิธีการเชื่อมต่อ 2 วิธี
- ใช้งาน Official WebHDFS และเขียนโปรแกรมเพื่อจัดการ Kerberized Connection เอง
- ใช้งาน Custom WebHDFS Hook/Sensor ที่ ฝวท. พัฒนาขึ้นเพื่อเชื่อมต่อ WebHDFS ได้ทันทีโดยให้ Import
from mea.hooks.webhdfs import WebHDFSHookหรือfrom mea.sensors.webhdf import WebHdfsSensor
Source Code ที่ ฝวท. แก้ไขเพื่อให้รองรับกับระบบของ กฟน. อยู่ที่ฟังก์ชั่น get_client โดยเพิ่มให้ KerberosClient สร้าง Connection จาก connection.schema แทนที่จะกำหนดตายตัวเป็น http:
def _get_client(self, connection: Connection) -> Any:
# We modified this line to allow KerberosClient
connection_str = f'{connection.schema}://{connection.host}:{connection.port}'
if _kerberos_security_mode:
client = KerberosClient(connection_str)
else:
proxy_user = self.proxy_user or connection.login
client = InsecureClient(connection_str, user=proxy_user)
return client
คุณสามารถดูตัวอย่างการใช้งานได้ที่ DAG HDFS
Apache Hive
คุณสามารถใช้ Apache Hive บน Data Platform ด้วยการกำหนด conn_id='sys-jdbc-hive' ร่วมกับ JDBCOperator คุณสามารถดูตัวอย่างการใช้งานได้ที่ DAG HDFS & Hive
Cloudera Impala
คุณสามารถใช้ Apache Impala บน Data Platform ด้วยการกำหนด conn_id='sys-jdbc-impala' ร่วมกับ JDBCOperator สามารถดูตัวอย่างได้ที่ DAG Impala
Apache Sqoop
Cloudera ของ กฟน. ไม่สนับสนุน Sqoop2 ที่มีโครงสร้าง Server - Client ทำให้ต้องใช้วิธีอื่นในการใช้งาน Sqoop ซอฟท์แวร์ของ Cloudera ปัจจุบันสามารถใช้งาน Sqoop1 ได้เพียงเวอร์ชั่นเดียว วิธีการใช้ร่วมกับ Apache Airflow ให้ใช้ SSHOperator โดยให้ระบุ ssh_conn_id='sys-ssh-sqoop' โดยมีขั้นตอนการใส่ Command ดังนี้
- ทำการ Initialize Kerberos principal ด้วยคำสั่ง
kinit -kt keytab/airflow.keytab airflow/airflow.mea.or.th - ทำการรันคำสั่ง
sqoop
ในกรณีที่ต้องกรอก Password ของการต่อ Database ขอให้ระมัดระวัง โดยใช้ Airflow Variable เข้ามาช่วย
from airflow.providers.ssh.operators.ssh import SSHOperator
with DAG(
dag_id="sys__sqoop_hive",
default_args=default_args,
tags=['sample', 'hive', 'sqoop'],
template_searchpath='/shared',
description="Using sqoop to pull data from RDBMS",
start_date=airflow.utils.dates.days_ago(1),
schedule_interval="@daily"
) as dag:
try_sqoop_import = SSHOperator(
task_id='try_sqoop_import',
ssh_conn_id='sys-ssh-sqoop',
command="""kinit -kt keytab/airflow.keytab airflow/airflow.mea.or.th &&\
sqoop list-databases --connect jdbc:sqlserver://<ip>:<port> --username <xxxx> --password <yyyy>
"""
)
try_sqoop_import
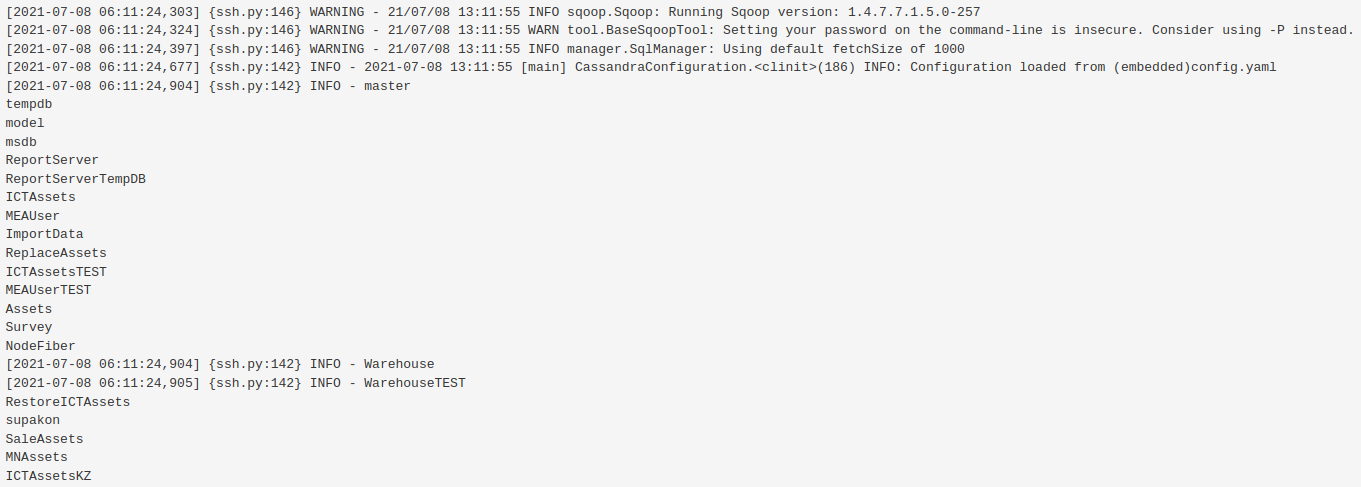
ตัวอย่าง Output จาก sqoop
Apache Spark
คุณสามารถใช้ Apache Spark บน Data Platform ได้โดยกำหนด conn_id='sys-spark-livy' ร่วมกับ LivyOperator แต่เนื่องจาก Official Source Code ของ ApacheLivyOperator ใช้ HTTPHook เป็นแกนหลักในการเชื่อมต่อกับ REST Services ซึ่งปัจจุบันยังไม่สนับสนุนการ Authenticate ด้วย Kerberos หรือ SPNEGO คุณมีวิธีเชื่อมต่อ 2 วิธี
- ใช้งาน Official LivyOperator และจัดการการเชื่อมต่อแบบ SPNEGO ด้วยตนเอง
- ใช้งาน Custom ApacheLivyOperator ที่ ฝวท. พัฒนา เพื่อ Submit Spark Job ได้ทันที โดยให้ Import from mea.operators.livy import LivyOperator
Source Code ที่ ฝวท. แก้ไขใน HTTP Hook คือ (1) Detect การเชื่อมต่อแบบ Kerberos (2) ทำการเชื่อมต่อผ่าน Kerberos ด้วย Python Package requests_gssapi
# We added this line to detect Airflow security config
_kerberos_security_mode = conf.get("core", "security") == "kerberos"
def get_conn(self, headers: Optional[Dict[Any, Any]] = None) -> requests.Session:
"""
Returns http session for use with requests
:param headers: additional headers to be passed through as a dictionary
:type headers: dict
"""
session = requests.Session()
if self.http_conn_id:
conn = self.get_connection(self.http_conn_id)
if conn.host and "://" in conn.host:
self.base_url = conn.host
else:
# schema defaults to HTTP
schema = conn.schema if conn.schema else "http"
host = conn.host if conn.host else ""
self.base_url = schema + "://" + host
if conn.port:
self.base_url = self.base_url + ":" + str(conn.port)
if conn.login:
session.auth = self.auth_type(conn.login, conn.password)
# We added these two lines to build SPNEGO auth session
if _kerberos_security_mode:
session.auth = HTTPSPNEGOAuth()
if conn.extra:
try:
session.headers.update(conn.extra_dejson)
except TypeError:
self.log.warning('Connection to %s has invalid extra field.', conn.host)
if headers:
session.headers.update(headers)
return session
คุณสามารถดูตัวอย่างการใช้งานได้ที่ DAG SPARK
Docker
ในกรณีที่คุณมี Docker Image และต้องการนำมาประมวลผลบน Apache Airflow คุณสามารถนำมาใช้งานกับ DockerOperator ได้ทันทีโดยไม่ต้องระบุ docker_url โดยทั่วไปขั้นตอนในการใช้งานจะเป็นดังนี้
- สร้าง Application ที่ต้องการ และ Build เป็น Docker Image
- Push Docker Image ไปที่ Docker Hub
- เขียน DAG โดยใช้ DockerOperator ระบุชื่อ Image ใน
image
คุณสามารถดูตัวอย่างการใช้งาน Docker ได้ที่ DAG Docker
ปัจจุบัน Apache Airflow Cluster ภายใน กฟน. ยังไม่สนับสนุน Kubernetes
Email Notification
คุณสามารถใช้ Feature Email Notification หรือ EmailOperator โดยไม่ต้อง Config เพิ่มเติม สามารถดูตัวอย่างได้ที่ DAG Email
MinIO Object Storage
MinIO เป็น Object Storage ที่สามารถใช้งานร่วมกับ Amazon S3 Operators ได้โดยกำหนด conn_id='sys-minio' โดยคุณสามารถ Access Bucket ได้ดังนี้
- READ/WRITE สำหรับ Bucket
airflow - READ สำหรับ Bucket
public
ในกรณีที่คุณต้องการใช้งาน Features ที่ไม่มีใน Operators/Hooks คุณสามารถใช้ Python Package minio ร่วมกับ MinIO Client API และ PythonOperator ในการใช้ Access MinIO ในกรณีนี้คุณจะต้องกำหนด Access Credentials ดังนี้
from airflow.models import Variable
from minio import Minio
client = Minio(
Variable.get('MINIO_HOST'),
access_key=Variable.get('MINIO_SECRET_ACCESS_KEY'),
secret_key=Variable.get('MINIO_SECRET_KEY'),
secure=False,
http_client=urllib3.ProxyManager('http://meaproxy.mea.or.th:80')
)
ดูตัวอย่างการใช้งาน S3Hook และ S3KeySensor ได้ที่ DAG MinIO #1
ดูตัวอย่างการดาวโหลดไฟล์ผ่าน Client API ได้ที่ DAG MinIO #2
Apache HBase & Apache Phoenix
Module happybase ไม่รองรับ Secure Connection ทำให้ไม่สามารถเชื่อมต่อกับ Secure HBase Cluster ของ กฟน. ได้ ปัจจุบัน กฟน. สนับสนุนการใช้งาน HBase 2 รูปแบบได้แก่
- HBase REST API ใช้งานเหมือน REST API ทั่วไป
- Apache Phoenix ใช้งาน HBase ด้วยภาษา SQL
ตัวอย่างการใช้งาน HBest REST API ผ่าน SPNEGO
import base64
import json
import requests
from typing import Dict, List
from requests_gssapi import HTTPSPNEGOAuth
HBASE_REST_ENDPOINT = 'https://dpc-cdr-m1.mea.or.th:20550'
DEFAULT_HEADERS = {
'Accept': 'application/json'
}
DEFAULT_AUTH = HTTPSPNEGOAuth()
class HBaseAPI:
DEFAULT_HOST = 'https://dpc-cdr-m1.mea.or.th'
DEFAULT_PORT = 20550
DEFAULT_AUTH = HTTPSPNEGOAuth()
def __init__(self, host: str = DEFAULT_HOST, port: int = DEFAULT_PORT, auth=DEFAULT_AUTH):
self._host = host
self._port = port
self._auth = auth
self._url = f'{self._host}:{self._port}'
self._session = requests.Session()
self._session.auth = self._auth
def _b64encode(self, s: str) -> str:
return base64.b64encode(s.encode('ascii')).decode('ascii')
def _b64decode(self, s: str) -> str:
return base64.b64decode(s.encode('ascii')).decode('ascii')
def get_cluster_version(self) -> str:
try:
response = self._session.get(f'{self._url}/version/cluster', headers={'Accept': 'application/json'})
response.raise_for_status()
except requests.exceptions.HTTPError as e:
raise SystemExit(e)
return response.json().get('Version')
def list_all_tables(self) -> str:
try:
response = self._session.get(f'{self._url}/', headers={'Accept': 'application/json'})
response.raise_for_status()
except requests.exceptions.HTTPError as e:
raise SystemExit(e)
return [table['name'] for table in response.json().get('table')]
def get_table_schema(self, name: str) -> Dict[str, str]:
try:
response = self._session.get(f'{self._url}/{name}/schema', headers={'Accept': 'application/json'})
response.raise_for_status()
except requests.exceptions.HTTPError as e:
raise SystemExit(e)
return response.json()
def create_table(self, name: str, cfs: List[str]) -> None:
headers = {
'Accept': 'application/json',
'Content-Type': 'application/json'
}
data = {
'@name': name,
'ColumnSchema': [{"name": cf} for cf in cfs]
}
try:
response = self._session.put(f'{self._url}/{name}/schema', headers=headers, data=json.dumps(data))
except requests.exceptions.HTTPError as e:
raise SystemExit(e)
def insert_data(self, name: str, data) -> None:
headers = {
'Accept': 'application/json',
'Content-Type': 'application/json'
}
try:
response = self._session.put(f'{self._url}/{name}/false-row-key', headers=headers, data=json.dumps(data))
response.raise_for_status()
except requests.exceptions.HTTPError as e:
raise SystemExit(e)
def get_row(self, name: str, rowkey: str) -> List[Dict[str, str]]:
try:
response = self._session.get(f'{self._url}/{name}/{rowkey}', headers={'Accept': 'application/json'})
except requests.exceptions.HTTPError as e:
raise SystemExit(e)
# Parse row
data = response.json()
return [{'column': self._b64decode(cell['column']),
'timestamp': cell['timestamp'],
'$': self._b64decode(cell['$'])}
for cell in data.get('Row')[0].get('Cell')]
def b64encode(s: str) -> str:
return base64.b64encode(s.encode('ascii')).decode('ascii')
if __name__=='__main__':
### Instantiate a simple HBaseAPI class
hbase = HBaseAPI()
### Example: Get HBase version
print(f'HBase version: {hbase.get_cluster_version()}')
### Example: Create table with column families
hbase.create_table('users_api', cfs=['personal', 'office'])
### Example: Insert data
data = {
"Row": [
{
"key": b64encode('1'),
"Cell": [
{"column": b64encode('personal:name'), "$": b64encode('Noctic Lucis Caelum')},
{"column": b64encode('personal:weapon'), "$": b64encode('Royal Arms')},
{"column": b64encode('office:city'), "$": b64encode('Insomnia')},
{"column": b64encode('office:transport'), "$": b64encode('Regalia Type-F')}
]
},
{
"key": b64encode('2'),
"Cell": [
{"column": b64encode('personal:name'), "$": b64encode('Jill Valentine')},
{"column": b64encode('personal:weapon'), "$": b64encode('Baretta')},
{"column": b64encode('office:city'), "$": b64encode('Raccoon City')},
{"column": b64encode('office:transport'), "$": b64encode('RPD Car')}
]
}
]
}
hbase.insert_data(name='users_api', data=data)
### Example: Query a single row
data = hbase.get_row(name='users_api', rowkey='1')
for cell in data:
print(cell)
ตัวอย่างวิธีการใช้งาน Apache Phoenix ผ่าน SPNEGO
import phoenixdb
import phoenixdb.cursor
from textwrap import dedent
from requests_gssapi import HTTPSPNEGOAuth
# Connect to Apache Phoenix using Kerberos
# If you're running this on MEA Airflow, you don't have to worry about kinit.
database_url = 'https://dpc-cdr-u2.mea.or.th:8765/'
drop_table_query = dedent('''\
DROP TABLE IF EXISTS "users_phoenix"
''')
create_table_query = dedent('''\
CREATE TABLE IF NOT EXISTS "users_phoenix" (
"id" INTEGER NOT NULL PRIMARY KEY,
"personal"."name" VARCHAR,
"personal"."weapon" VARCHAR,
"office"."city" VARCHAR,
"office"."transport" VARCHAR
)
''')
upsert_table_query = dedent('''\
UPSERT INTO "users_phoenix" ("id", "personal"."name", "personal"."weapon", "office"."city", "office"."transport")
VALUES (?, ?, ?, ?, ?)
''')
data_query = dedent('''\
SELECT * FROM "users_phoenix"
''')
with phoenixdb.connect(database_url, autocommit=True, auth=HTTPSPNEGOAuth()) as connection:
with connection.cursor() as cursor:
cursor.execute(drop_table_query)
cursor.execute(create_table_query)
cursor.executemany(upsert_table_query,
[
[1, 'Noctis Lucis Caelum', 'Royal Arms', 'Insomnia', 'Regalia Type-F'],
[2, 'Jill Valentine', 'Baretta', 'Raccoon City', 'RPD Car']
])
cursor.execute(data_query)
for row in cursor:
print(row)