การใช้งาน Apache Spark
คุณสามารถใช้งาน Apache Spark บน Data Platform ได้หลายวิธี ตามรายละเอียดในคู่มือนี้ แต่ถ้าคุณไม่แน่ใจว่าจะเริ่มจากตรงไหน แนะนำให้ใช้ Interactive Spark ผ่าน Command Line เนื่องจากไม่ต้องตั้งค่าเยอะ และ เห็นผลลัพธ์ได้ทันที
การใช้งาน Spark ผ่าน Cloudera Hue
คุณสามารถศึกษาขั้นตอนการ Submit Spark Application ผ่าน Cloudera Hue ได้ที่ คู่มือการใช้งาน Hue
การใช้งาน Spark ผ่าน Apache Airflow
ในกรณีที่คุณต้องสร้าง Data Pipelines ที่ต้องการประมวลผลข้อมูลขนาดใหญ่ ดูวิธีการ Submit Spark Job ผ่าน Apache Airflow ได้ที่ คู่มือการใช้งาน Apache Airflow
การใช้งาน Apache Spark Shell
การ Login เข้า Data Platform Shell
เปิดโปรแกรม Microsoft PowerShell (ปกติจะติดตั้งอยู่บน Windows แล้ว), Microsoft Terminal หรือ MobaXterm จากนั้นพิมพ์คำสั่งด้านล่างเพื่อ Login เข้า Data Platform ใช้ Password เดียวกับระบบ AD (ชุดเดียวกับที่ใช้ Login WiFi กฟน.)
ssh <รหัสพนักงาน>@dpc-cdr-u1.mea.or.thตัวอย่างเช่น พนักงานรหัส
2237007สามารถเข้าใช้งานด้วยการใช้คำสั่งssh 2237007@dpc-cdr-u1.mea.or.thหลังจากใส่ Password คุณจะเห็น Prompt สำหรับการทำงาน

พิมพ์คำสั่งด้านล่างเพื่อขอ Ticket ในการใช้ Services ต่างๆจากระบบความปลอดภัย Kerberos เมื่อระบบถามพาสเวิร์ด ให้ใส่พาสเวิร์ดจากระบบ AD
kinit <รหัสพนักงาน>@MEANET.MEA.OR.THตัวอย่างเช่น พนักงานรหัส
2237007ขอ Ticket ด้วยคำสั่งkinit 2237007@MEANET.MEA.OR.THตรวจสอบสถานะ Ticket ด้วยคำสั่ง
klistตามรูป
การใช้งาน Interactive Spark
พิมพ์คำสั่ง
pysparkเพื่อเริ่มใช้งาน SparkLinuxData Platform ใช้ระบบปฎิบัติการ RHEL (Red Hat Enterprise Linux) คุณสามารถใช้คำสั่ง Linux ได้ตามปกติ หากคุณไม่คุ้นเคยกับ Linux คุณจะได้เรียนรู้พื้นฐานจากหลักสูตร Data Scientist และ Data Engineering
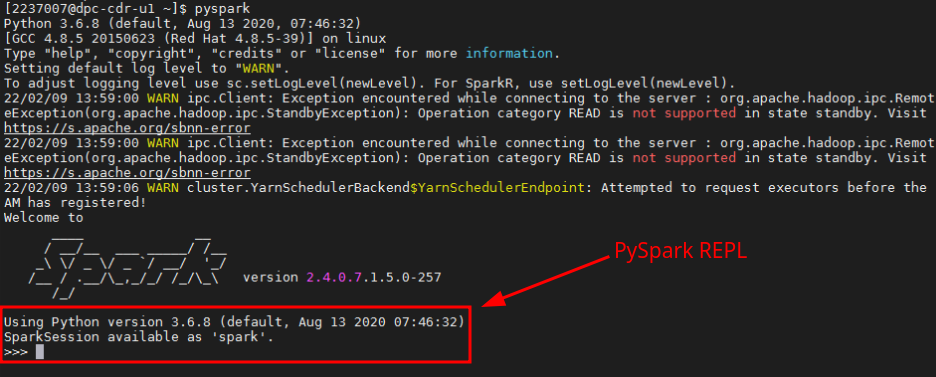
PySpark จะสร้างตัวแปร
spark(SparkSession) ให้อัตโนมัติ โดยมีการเชื่อมต่อกับระบบภายในของ Data Platform เช่น HDFS และ Hive แล้ว คุณสามารถใช้sparkในการเขียนโปรแกรมประมวลผลข้อมูลได้ทันที
ตัวอย่าง - การอ่านไฟล์ CSV จาก HDFS
คุณสามารถใช้ Path HDFS ได้โดยไม่ต้องใส่ hdfs:// เช่น /user/airflow/sample-data/sample-data.csv
df = spark.read.csv('/user/airflow/sample-data/sample-data.csv', header=True)
df.show()
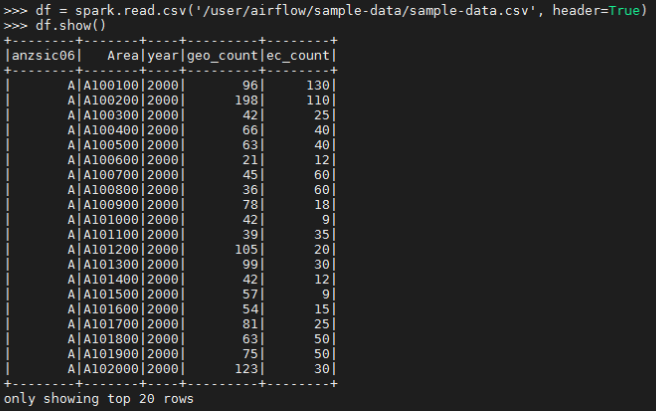
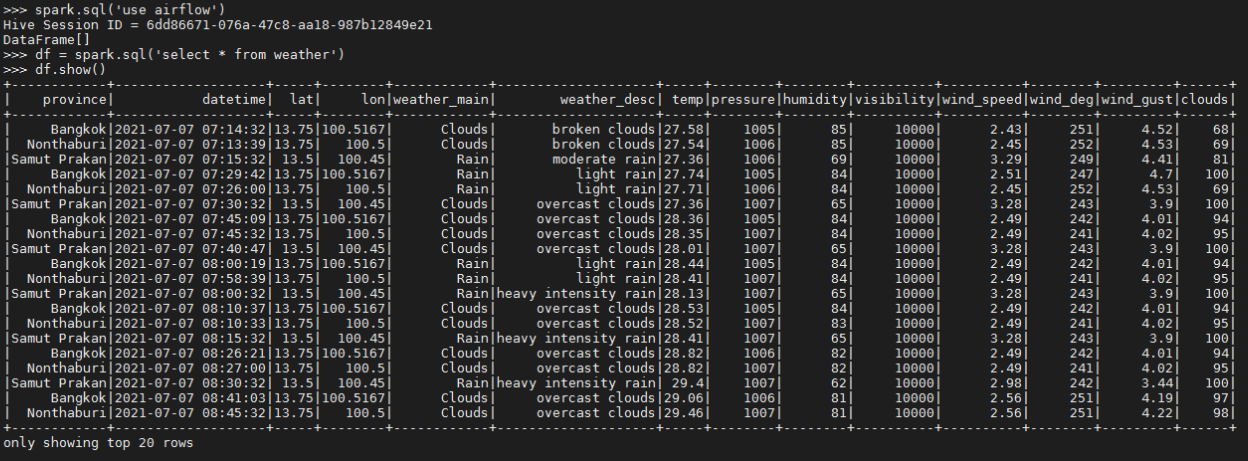
ตัวอย่าง - การอ่านข้อมูลจาก Hive
คุณสามาถใช้ SQL ในการอ่านข้อมูลจาก Hive Tables ได้ทันที ในตัวอย่างจะแสดงการอ่านตาราง weather จาก Database ชื่อ airflow และ แสดงข้อมูล 20 แถวแรก
spark.sql('use airflow')
df = spark.sql('select * from weather')
df.show()
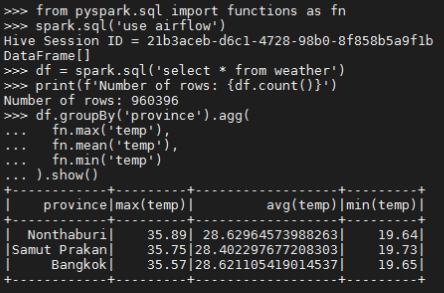
ตัวอย่าง - การหาค่า Max, Min และ Mean ของชุดข้อมูล Weather
from pyspark.sql import functions as fn
# Use 'airflow' database
spark.sql('use airflow')
# Query weather info from the table
df = spark.sql('select * from weather')
# Print the number of rows
print(f'Number of rows: {df.count()}')
# Find Min, Max and Mean
df.groupBy('province').agg(
fn.max('temp'),
fn.mean('temp'),
fn.min('temp')
).show()
การ Submit Spark Job ผ่าน Command Line
คุณสามารถ Submit Spark Job ด้วยคำสั่ง spark-submit ได้ที่ Linux Command Line
การ Submit จาก Local File
ในกรณีที่คุณมีไฟล์ .py ใน User Directory บนเครื่อง Data Platform dpc-cdr-u1.mea.or.th คุณสามารถใช้คำสั่ง
spark-submit <filename> <argument_0> <argument_1> ..
เช่น ต้องการรันโปรแกรม py-estimation.py ที่เซฟไว้บนเครื่อง dpc-cdr-u1.mea.or.th คุณสามารถใช้คำสั่งดังนี้
spark-submit pi-estimation.py 10
ตัวอย่าง PySpark โปรแกรม
import sys
from random import random
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
"""
Usage: pi [partitions]
"""
spark = SparkSession\
.builder\
.appName("PythonPi")\
.getOrCreate()
partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partitions
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
spark.stop()
หลังจาก Submit แล้วจะได้ผลลัพธ์ตามรูป

การ Submit จาก HDFS
ในกรณีที่คุณเก็บ PySpark source file .py ไว้บน HDFS คุณสามารถ Submit ได้ด้วยคำสั่ง
spark-submit hdfs://<hdfs_path> <argument_0> <argument_1> ...
เช่น ต้องการรันโปรแกรม pi-estimation.py ที่เซฟไว้บน HDFS Path /user/2237007/pi-estimation.py
spark-submit hdfs:///user/2237007/pi-estimation.py 10