Tutorial
Course Materials
ดาวโหลด Source Code สำหรับการทดลอง
Outline
จุดประสงค์หลัก แนะนำสถาปัตยกรรม ช่องทางวิธีการใช้งาน Data Platform ของ กฟน. สำหรับงานวิศวกรรมข้อมูล

Data Platform Architecture
Overview
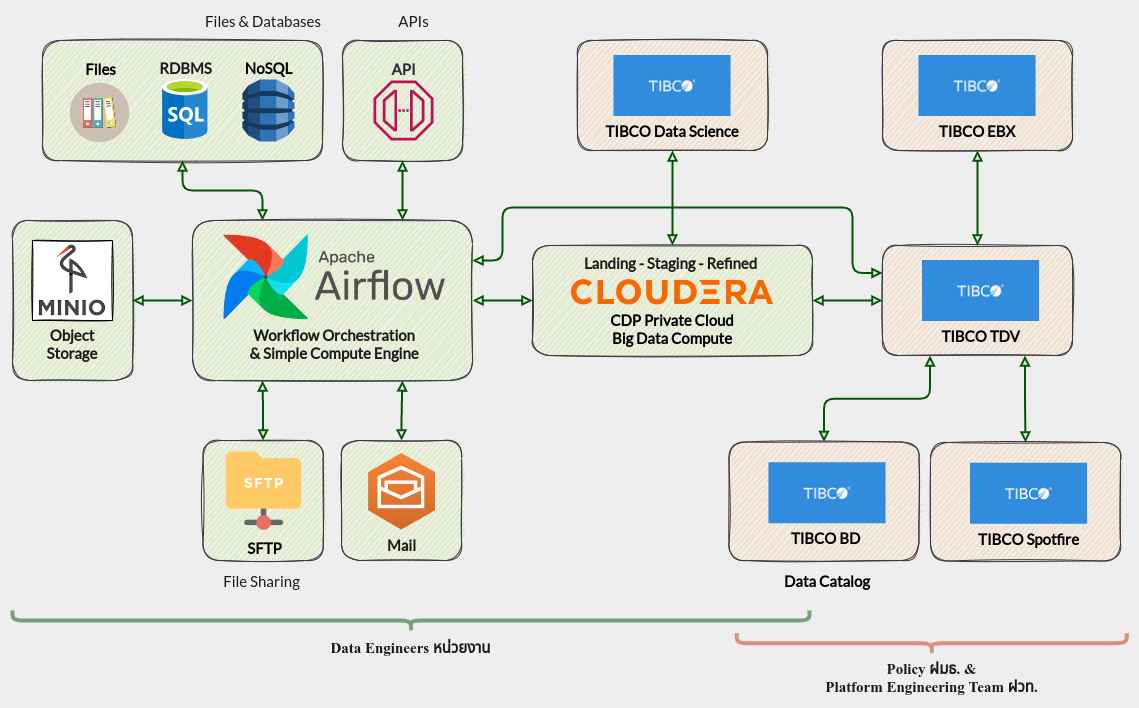
Big Data Tools

General Workflow
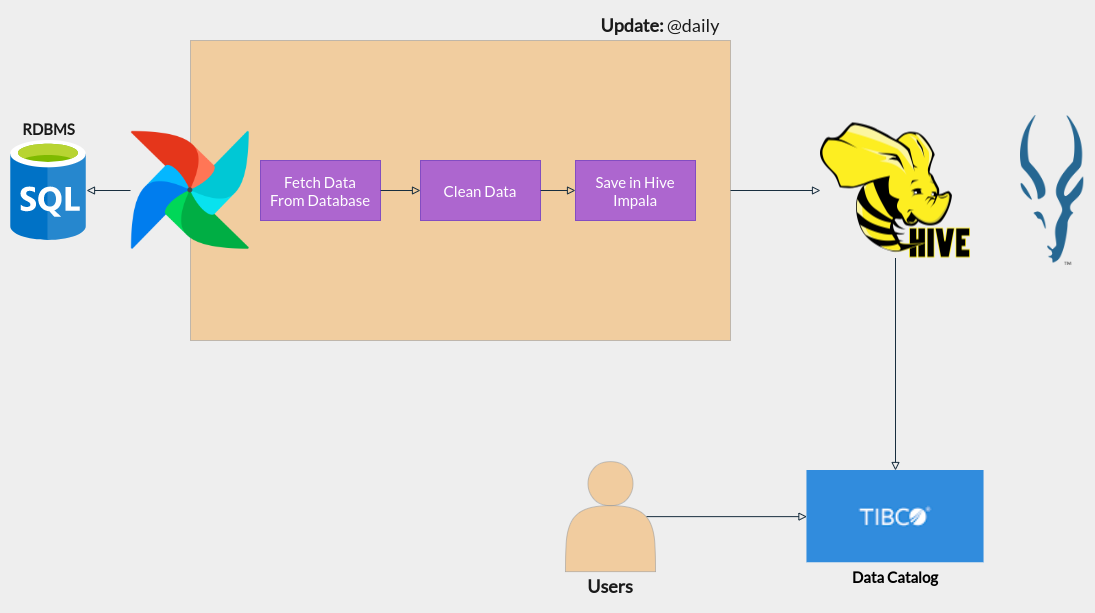
Linux Basics
List Files
ls
ls /bin
ls -l /bin
Print Working Directory
pwd
Change Directory
cd /bin
เปลี่ยนกับมาที่ Home Directory
cd ~
หรือ
cd /home/student
Make a Directory
mkdir <directory_name>
เช่น
mkdir mydata
Copy a File
cp <source> <destination>
เช่น
cp hello.py Documents/hello.py
Move/Rename a File
mv <source> <destination>
เช่น
mv hello.py Documents/hello_v2.py
Remove a File
rm <filename>
เช่น
rm hello.py
Show Contents
cat <filename>
เช่น
cat hello.py
Edit a File from CLI
nano <filename>
เช่น
nano hello.py
Download a File from Web
wget <url>
เช่น
wget https://www.google.com
HDFS
CLI - Login
ใน Data Engineering VM ไปที่ Applications > System Tools > Terminal
Log in เข้าเครื่อง Data Platform
dpc-cdr-u1.mea.or.thด้วย Username/Password จากระบบ ADssh <employee_id>@dpc-cdr-u1.mea.or.thเช่น รหัสพนักงาน
2237007ใช้ssh 2237007@dpc-cdr-u1.mea.or.thหลังจากที่เข้าเครื่อมาได้แล้วจะต้องทำการยืนยันตัวตนใน Network เพื่อขอ Tickets ใช้งาน Tools ภายใต้ Data Platform Cluster ใช้คำสั่ง
kinit <employee_id>@MEANET.MEA.OR.THเช่น
kinit 2237007@MEANET.MEA.OR.THตรวจสอบว่าได้รับ Tickets ในการใช้งานด้วยคำสั่ง
klist
CLI - HDFS
ระบบ Data Platform รองรับคำสั่ง Hadoop ทั้งสองรูปแบบทั้ง hadoop fs และ hdfs dfs โดยมีความแตกต่างดังนี้
hadoop fsใช้ได้กับหลาย File System เช่น Local, HDFS, S3, (S)FTPhdfs dfsใช้กับ HDFS เท่านั้น
ตัวอย่าง
hadoop fs -ls file:///home/2237007@meanet.mea.or.th/Downloads
การใช้งานสามารถใช้คำสั่ง Hadoop Management ได้ตามปกติ เช่น
List Files
hdfs dfs -ls
Copy From Local
นำไฟล์จากเครื่อง Local ขึ้นไปเก็บที่ Hadoop File System
hdfs dfs -copyFromLocal pi-estimation.py .
Copy To Local
ดาวโหลดไฟล์จาก HDFS มาเก็บไว้ที่เครื่อง
hdfs dfs -copyToLocal pi-estimation.py
Create a Directory
สร้าง Folder ใหม่บน HDFS
hdfs dfs -mkdir de-tutorial
Change Directory
hdfs dfs -cd de-tutorial
Remove a Directory
ลบ Directory บน HDFS
hdfs dfs -rmdir de-tutorial
Get Help
รายละเอียดคำสั่งและการใช้งานต่างๆ
hdfs dfs -h
GUI - Login
ที่เครื่อง Virtual Machine ไปที่ Applications > System Tools > Terminal
ทำการยืนยันตัวตนใน Network เพื่อขอ Tickets ใช้งาน Tools ภายใต้ Data Platform Cluster ใช้คำสั่ง
kinit <employee_id>@MEANET.MEA.OR.THเช่น
kinit 2237007@MEANET.MEA.OR.THตรวจสอบว่าได้รับ Tickets ในการใช้งานด้วยคำสั่ง
klistเปิดเว็บ Hue ที่ https://dpc-cdr-u1.mea.or.th:8889 เพื่อเข้าใช้งาน Hue UI เข้าใช้งานผ่าน Network ภายในของ กฟน. เท่านั้น
รายละเอียดเกี่ยวกับการใช้งานหน้าจอ Hue อ่านเพิ่มเติมได้ที่คู่มือการใช้งาน Cloudera Hue
Hive & Impala
Hive ใน Data Platform ใช้ Tez ในการประมวลผลทดแทน MapReduce ผู้ใช้งานเขียน SQL เพื่อประมวลผลข้อมูล เหมือนปกติ Engine จะทำการแปลง Code ให้อัตโนมัติโดยไม่ต้องกังวลถึงความแตกต่างจาก MapReduce Hive เหมาะกับงานประเภท Batch Processing
Impala เป็น Query Engine ประสิทธิภาพสูงที่ถูกออกแบบสำหรับงาน Ad-hoc Query (Interactive Query) สามารถใช้ SQL มาตรฐานในการประมวลผลข้อมูล
Hue UI
ที่เครื่อง Virtual Machine ไปที่ Applications > System Tools > Terminal
ทำการยืนยันตัวตนใน Network เพื่อขอ Tickets ใช้งาน Tools ภายใต้ Data Platform Cluster ใช้คำสั่ง
kinit <employee_id>@MEANET.MEA.OR.THเช่น
kinit 2237007@MEANET.MEA.OR.THตรวจสอบว่าได้รับ Tickets ในการใช้งานด้วยคำสั่ง
klistเปิดเว็บ Hue ที่ https://dpc-cdr-u1.mea.or.th:8889 เพื่อเข้าใช้งาน Hue UI เข้าใช้งานผ่าน Network ภายในของ กฟน. เท่านั้น
รายละเอียดเกี่ยวกับการใช้งานหน้าจอ Hue อ่านเพิ่มเติมได้ที่คู่มือการใช้งาน Cloudera Hue
Hive Query Sample
ตัวอย่างการใช้งาน
SELECT
*
FROM
weather
WHERE
province='Bangkok' AND weather_main='Rain'
DESCRIBE weather
สามารถคลิกขวาที่ชื่อ Table แล้วเลือก Open in Browser เพื่อดูรายละเอียดตารางได้เหมือนกัน
Impala Query Sample
ตัวอย่างการใช้งาน
SELECT
province,
MIN(temp) as min_temp,
AVG(temp) as avg_temp,
MAX(temp) as max_temp
FROM
weather
GROUP BY province
หรือทดสอบข้อมูลขนาดประมาณ 60GB
SELECT
year(clearing_date) as `year`,
COUNT(*) as tx_count
FROM
idd_payment
GROUP BY year(clearing_date)
Hive/Impala Use Case
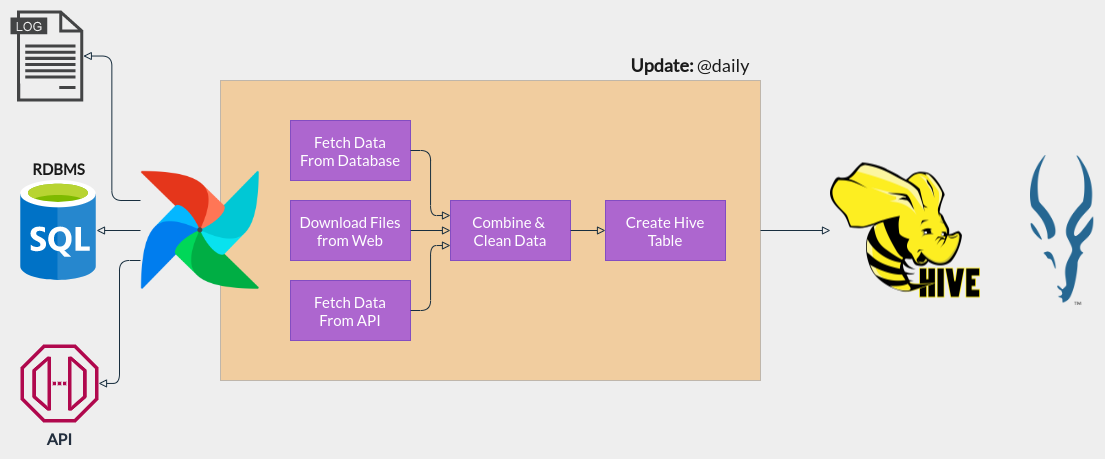
Spark
Spark คือ Processing Engine ที่สามารถทำงานบน Cluster และ ประมวลผลข้อมูลขนาดใหญ่อย่างมีประสิทธิภาพโดยประมวลผลได้ทั้ง Batch และ Stream นอกจากนี้ยังสามารถใช้ Spark ในงาน Data Science ได้ด้วยเนื่องจากมี Machine Learning Library สำหรับข้อมูลขนาดใหญ่ ใน Data Platform Spark เป็นเวอร์ชั่น 2.4 และสนับสนุนการใช้งานภาษาหลายรูปแบบ เช่น Python, Java, R และ Scala
Spark CLI
ใน Data Engineering VM ไปที่ Applications > System Tools > Terminal
Log in เข้าเครื่อง Data Platform
dpc-cdr-u1.mea.or.thด้วย Username/Password จากระบบ ADssh <employee_id>@dpc-cdr-u1.mea.or.thเช่น รหัสพนักงาน
2237007ใช้ssh 2237007@dpc-cdr-u1.mea.or.thหลังจากที่เข้าเครื่อมาได้แล้วจะต้องทำการยืนยันตัวตนใน Network เพื่อขอ Tickets ใช้งาน Tools ภายใต้ Data Platform Cluster ใช้คำสั่ง
kinit <employee_id>@MEANET.MEA.OR.THเช่น
kinit 2237007@MEANET.MEA.OR.THตรวจสอบว่าได้รับ Tickets ในการใช้งานด้วยคำสั่ง
klistเข้าใช้งาน
pyspark(Spark for Python) ด้วยคำสั่งpyspark
Interactive Spark
ตัวอย่าง PySpark ในการประมวลผลข้อมูลขนาดใหญ่ ในกรณีใช้งาน pyspark REPL สามารถใช้ spark (SparkSession) ได้เลยไม่ต้องสร้างเองเนื่องจากมีการตั้งค่าไว้เรียบร้อยแล้ว
อ่าน File CSV จาก HDFS
df = spark.read.csv('/user/airflow/sample-data/sample-data.csv', header=True)
df.show()
อ่านข้อมูลจาก Hive
spark.sql('use airflow')
df = spark.sql('SELECT * FROM weather')
df.show()
df.count()
ตัวอย่าง ประมวลผลข้อมูลสภาพอากาศ
from pyspark.sql import functions as fn
# Use 'airflow' database
spark.sql('use airflow')
# Query weather info from the table
df = spark.sql('select * from weather')
# Print the number of rows
print(f'Number of rows: {df.count()}')
# Find Min, Max and Mean
df.groupBy('province').agg(
fn.max('temp'),
fn.mean('temp'),
fn.min('temp')
).show()
Submit a Spark Job (CLI)
ผู้ใช้งานสามารถเขียนโปรแกรม Python และนำมารันบน Cluster ได้ด้วยคำสั่ง
spark-submit <filename> <arguments>
ตัวอย่าง
spark-submit pi-estimation.py 10
ตัวอย่าง Source Code pi-estimation.py
import sys
from random import random
from operator import add
from pyspark.sql import SparkSession
if __name__ == "__main__":
"""
Usage: pi [partitions]
"""
spark = SparkSession\
.builder\
.appName("PythonPi")\
.getOrCreate()
partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partitions
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 <= 1 else 0
count = spark.sparkContext.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
spark.stop()
Submit a Spark Job (GUI)
เข้าใช้งาน Hue และ Submit Spark Job ผ่าน GUI
Spark Use Case
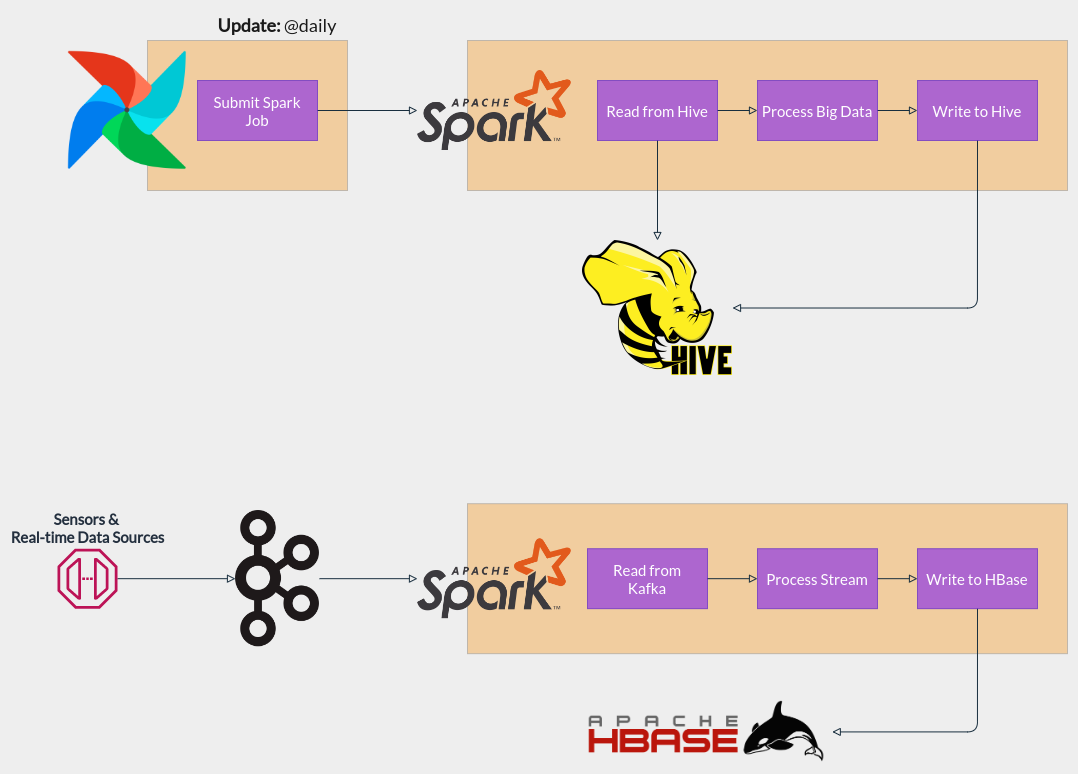
HBase
HBase CLI
ใน Data Engineering VM ไปที่ Applications > System Tools > Terminal
Log in เข้าเครื่อง Data Platform
dpc-cdr-u1.mea.or.thด้วย Username/Password จากระบบ ADssh <employee_id>@dpc-cdr-u1.mea.or.thเช่น รหัสพนักงาน
2237007ใช้ssh 2237007@dpc-cdr-u1.mea.or.thหลังจากที่เข้าเครื่อมาได้แล้วจะต้องทำการยืนยันตัวตนใน Network เพื่อขอ Tickets ใช้งาน Tools ภายใต้ Data Platform Cluster ใช้คำสั่ง
kinit <employee_id>@MEANET.MEA.OR.THเช่น
kinit 2237007@MEANET.MEA.OR.THตรวจสอบว่าได้รับ Tickets ในการใช้งานด้วยคำสั่ง
klistเข้าใช้งาน HBase ด้วยคำสั่ง
hbase shell
HBase Query
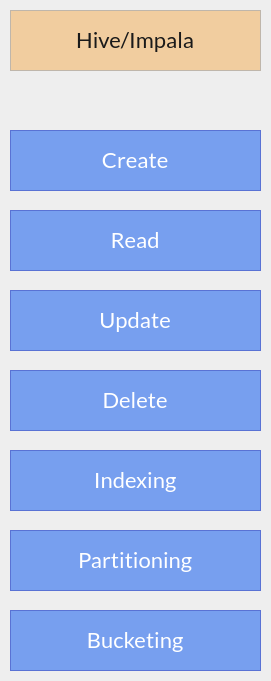
HBase เป็น NoSQL Database ที่เหมาะกับข้อมูลขนาดใหญ่มาก และต้องการใช้งานแบบ Random & Realtime มีสถาปัตยกรรมคล้ายกับ Google Bigtable แต่ใช้บน Hadoop และ HDFS ในตัวอย่างจะลองใช้ HBase Shell ในการ Query ข้อมูลที่มีโครงสร้างตามรูป
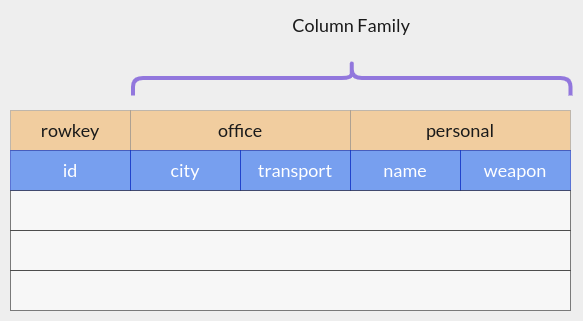
คำสั่งพื้นฐาน
Show User
whoami
Status & Version
status
version
List Tables
list
Scan Tables
scan 'users_api'
Read a Record
get 'users_api', '1'
get 'users_api', '1', {COLUMN => 'office:city'}
Create a Record
put 'users_api', '3', 'office:city', 'Bangkok'
put 'users_api', '3', 'office:tranport', 'Bus'
put 'users_api', '3', 'personal:name', 'Jonathan'
put 'users_api', '3', 'personal:weapon', 'Fists'
Apache Airflow
Architecture
Airflow ใน กฟน. ติดตั้งแบบ Celery Executor มี Node ประมวลผล 15 Nodes ทรัพยากรเครื่องโดยรวม 92 vCPU และ 312 GB RAM เหมาะสำหรับการใช้งานประเภท
- ประมวลผลและทำความสะอาดข้อมูลทั่วไป
- สร้าง Data Pipeline ที่ทำให้ Data Flow จากต้นทางไปยังปลายทาง
- สามารถเชื่อมต่อกับ Databases ได้หลากหลายประเภท ทำงานกับ Public Cloud และ Data Platform ภายใน กฟน. ได้
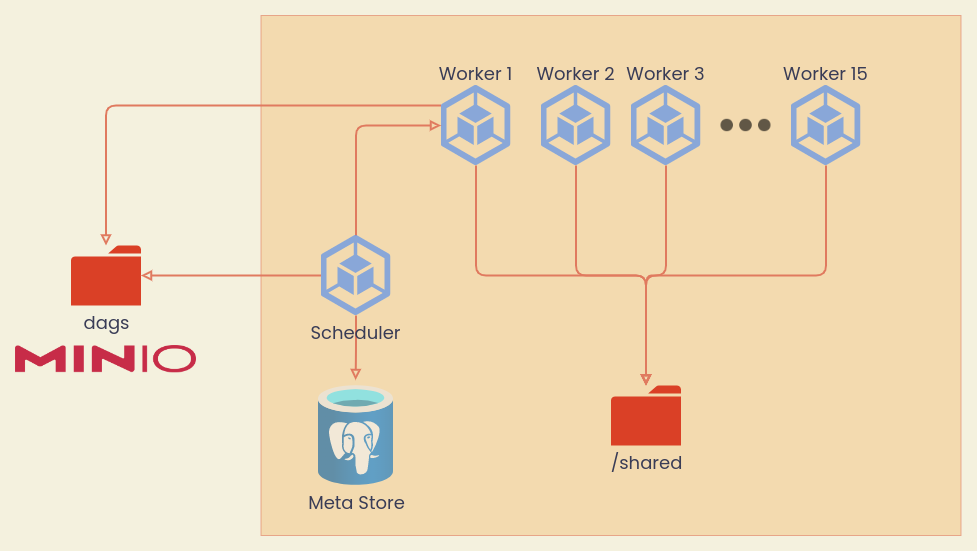
จุดสำคัญ
- Airflow อ่าน DAGs จาก Bucket ชื่อ dags ใน MinIO มีการซิงค์ข้อมูลทุกๆ 1 นาที
- Airflow เชื่อมต่อกับ Data Platform Services หลังบ้าน เช่น Hive, Impala, HBase, Spark
- Airflow เชื่อมต่อกับฐานข้อมูลใน MEA บางส่วน เช่น SAP SFTP, SAP/AMR Oracle Database, OT MSSQL Database, etc.
- Airflow Server มี 92 vCPUs และ 312 GB RAM
กระบวนงานพื้นฐาน
- เขียน DAGs ด้วยภาษา Python
- Log in เข้าใช้งาน MinIO Server และให้อัพโหลดไฟล์ .py เข้าไปที่ Bucket ชื่อ dags.
- ถ้าไม่มีข้อผิดพลาด Airflow จะทำการซิงค์ DAGs ภายใน 2 - 3 นาที ถ้ามีความผิดพลาดหน้าต่าง UI จะแจ้ง
- เข้าไปตรวจสอบและบริหารจัดการ DAGs ได้ที่ Airflow Web UI.
Basic Components
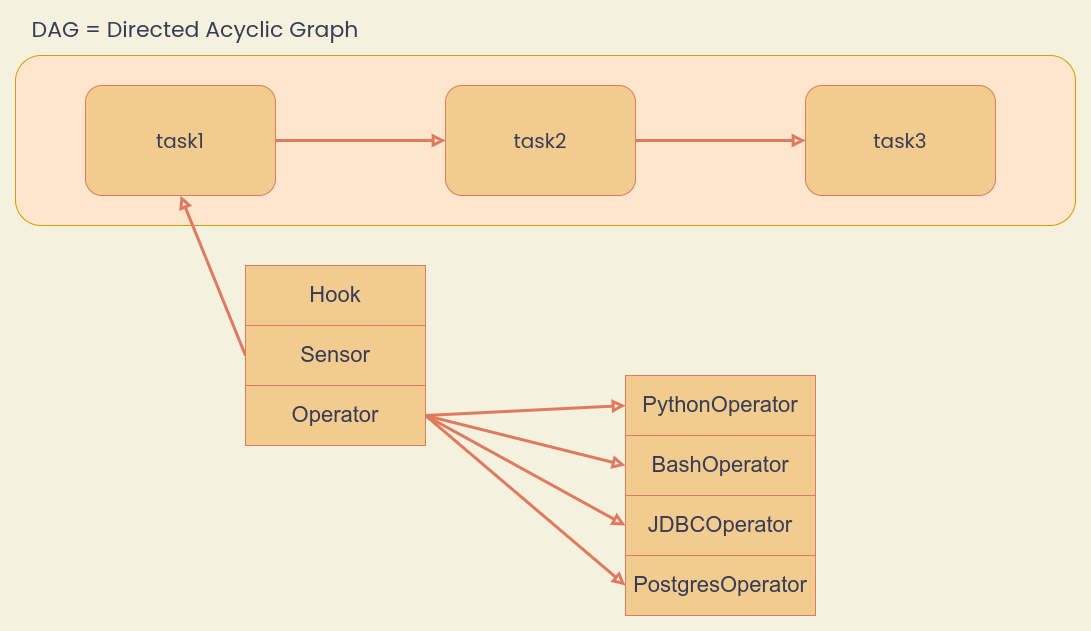
การเขียนโปรแกรมในแต่ละ Task ส่วนใหญ่จะใช้ Components อย่างใดอย่างหนึ่งได้แก่
- Hooks ใช้บริหารจัดการ Connection กับ Data Source (Files, Databases, API, etc.) เช่น WebHDFSHook ใช้สื่อสารกับ HDFS บน Data Platform
- Sensors ใช้ตรวจจับเหตุการณ์ที่สนใจ เช่น HTTPSensor ใช้ตรวจจับการสื่อสารแบบ HTTP
- Operators ใช้ทำงานตามฟังก์ชั่นที่กำหนด เช่น PythonOperator ใช้รันฟังก์ชั่น Python, PostgresOperator ใช้ทำงานกับ PostgreSQL Database เป็นต้น
รายละเอียดเพิ่มเติม Operators & Hooks
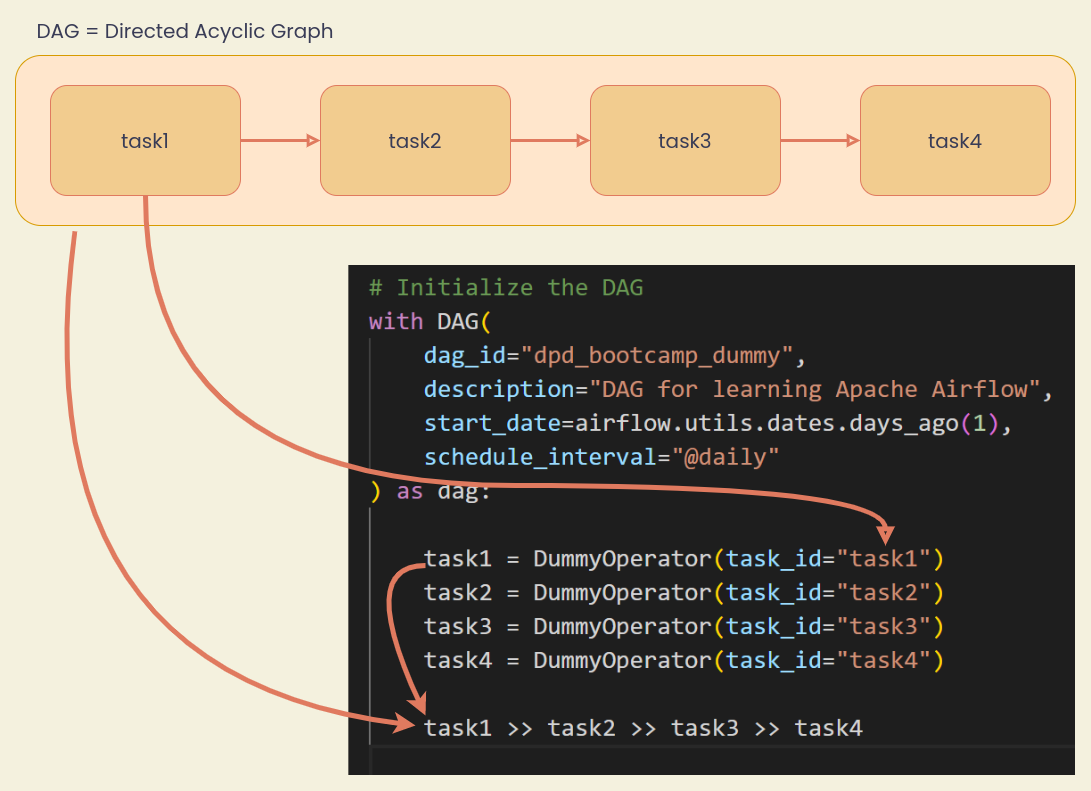
Sample 1 - Dummy DAG
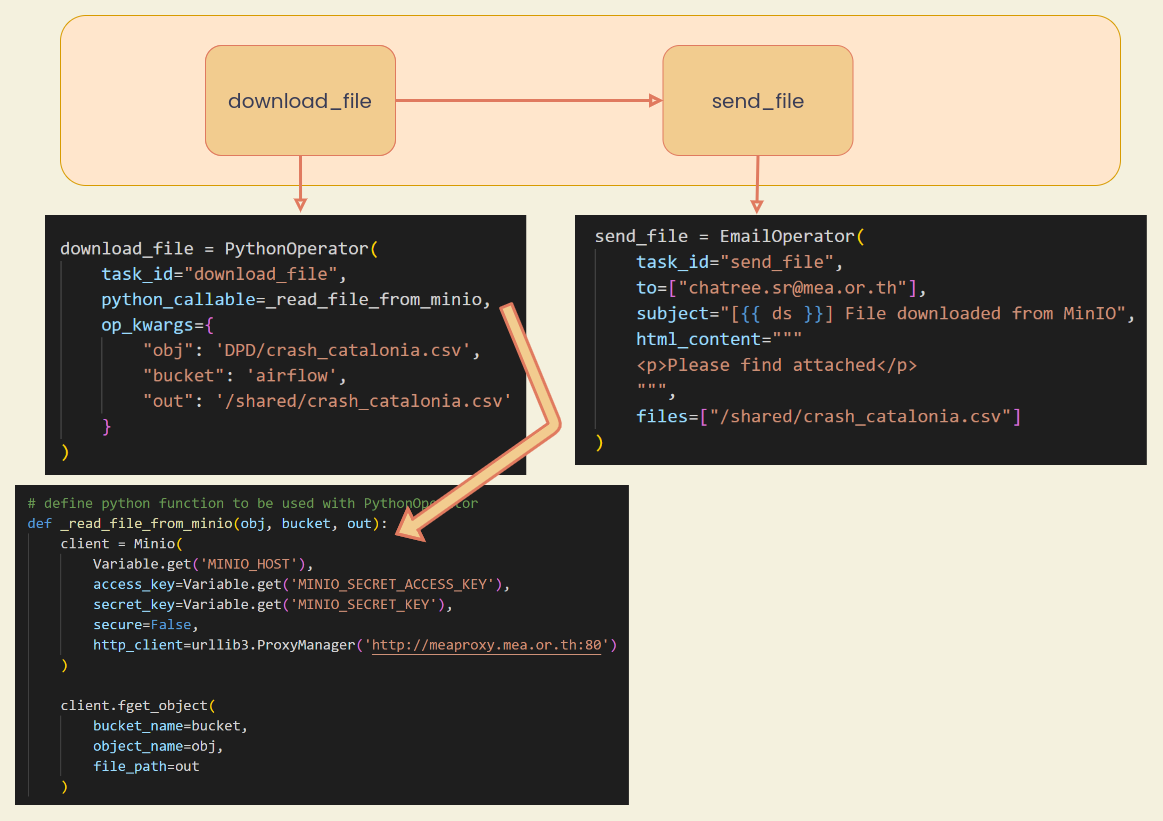
Sample 2 - MinIO to Email
Compatible Databases & Guides
อ่านรายละเอียดเพิ่มเติมที่ Apache Airflow